Four weeks ago I pushed the first commit of FlavorPress with another Automattician and a one-sentence pitch: your reading turns into your writing.
Today, with RSM behind me and 223 commits on the board, I want to write down what actually happened. Not a launch post. A real account of the decisions, the pivots, and the things that turned out to matter.

What FlavorPress is
FlavorPress is a writing companion for niche bloggers. It watches the RSS feeds, blogs, podcasts, and YouTube channels you already follow, groups stories into clusters when 3 or more outlets cover the same event, ranks them by relevance to your beat, and streams a 600-word draft in your voice directly into WordPress.

The target user runs a 60–90 minute morning reading routine and wants the writing step to take 15 minutes instead of 60. That’s it. That’s the whole product.
The stack: Next.js on Vercel, Turso (SQLite at the edge), Anthropic Claude for clustering embeddings and draft generation, and a WordPress Application Password integration for publishing.
Day one: we almost built the wrong thing
The first version of FlavorPress was called Flavor and it was supposed to work for solo bloggers AND enterprise newsrooms with 30 regional brands and AP/Reuters/DPA wire feeds. Same product, different config.
That was a mistake we caught early. A few days in, Matthias and I took a step back. The scope was drifting toward “do everything content-y for everyone with a WordPress site.” So we cut.
The new framing was one sentence: every feature, code change, ticket, UX decision, and architectural choice had to move reading → writing. We defined what that meant concretely: the user’s existing reading turns into a WordPress draft on their site, in their voice, on the same day, without becoming an AI slop factory.
What “no AI slop” means in the product: inline attribution links to every source paragraph the draft leans on. Real quoted passages preserved verbatim. A voice-match score the user can see, with the specific cues that pushed it up or down. Pull, not push — no daily auto-drafts, no notifications. The user opens FlavorPress when they want to write, and we earn the next visit by being useful.
What we cut: multi-site routing, multi-tenant voice adaptation, wire services as a source category, the cross-web trending feed. What we added in their place: voice capture from the user’s own WordPress posts (their site is the corpus), OPML import (fastest path from “I already read these” to “Flavor reads them too”), and a single-site first flow.
Less surface, sharper product.
Building with guardrails: the Agent.MD rule
I built the prototype during an AI Enablement training day. My setup: Conductor (Codex & Claude) with an Agent.MD file that encoded the mission as a 7-question test every agent had to run before accepting a feature request.
The test: does this feature move reading → writing? Does it respect the user’s existing routine? Does it produce a same-day draft? Is it in the user’s voice? Does it avoid AI slop? Is it pull, not push? Does it fit the deployment model?
Output: KEEP, DEFER, or DROP.
6 out of 31 of my own requests got rejected by my own bots. That was the right call every time. The Agent.MD rule means the AI is never allowed to drift from the mission either. When AI removes the build constraint, scope discipline does the work.
36 commits on the first prototype day. The full loop was working — sources I already read turning into a WP draft on my site, in my voice, on the same day.
The architecture bet that paid off
The most important early decision was the capability registry. Every internal feature — cluster engine, voice generator, fact-check, originality check, source connectors — is a manifest in a registry. The MCP server at /api/mcp exposes them to Claude Desktop and other AI agents using the same contract.
It felt over-engineered on day one. By week three I was shipping autopublish workflows, paid editor extensions, and admin extension controls in hours because the contract was already there. The capability registry was the right abstraction.
Week two: desktop assumptions are invisible until you go SaaS
The prototype ran perfectly on local SQLite. One user, one data shape, the user’s machine absorbed the cost. Moving to Vercel changed the physics.
First symptoms: /login took 30 seconds once. /today loaded in 1.5–2 seconds even after we thought we’d cached the expensive work. /sources and /reader had the same disease in smaller forms.
The underlying problem wasn’t one bad query. It was a desktop assumption leaking through the whole stack: “just ask the database right now.”
Today was the clearest case. The page was doing heavy cluster work, freshness checks, stats, outlet metadata, and cache validation before the user saw anything useful. We moved it to background refresh with a per-user view cache. But the first version still missed the point — it cache-busted too aggressively whenever feeds ingested new items. The better shape: keep showing the last good payload, mark it stale with a per-user version counter, refresh in the background, and only swap when the new payload is ready.
The same pattern showed up differently across pages. /sources needed indexes and fewer correlated subqueries, not a view cache. /reader needed a partial index for the unread deck and to stop running leading-wildcard title scans. /editor/[draftId] needed independent queries in parallel.
The SaaS lesson: “make it async” is not enough. Async work helps when the work is genuinely expensive and the user can accept stale state. It does not fix missing indexes, N+1 queries, or serialized awaits. Those are still bugs.
The real scaling step is learning where freshness actually matters. Sources and reader actions should feel immediate — they’re direct manipulation. Today can tolerate stale lanes for a few seconds — the user is reading and choosing. Stats can lag. Diagnostics can lag. The draft editor cannot lag once opened. A SaaS app has to answer that question per page: what must be fresh before first paint, what can be stale, what can be fetched after interaction, what should be precomputed when data changes.
Week three: the missing step in reading → writing
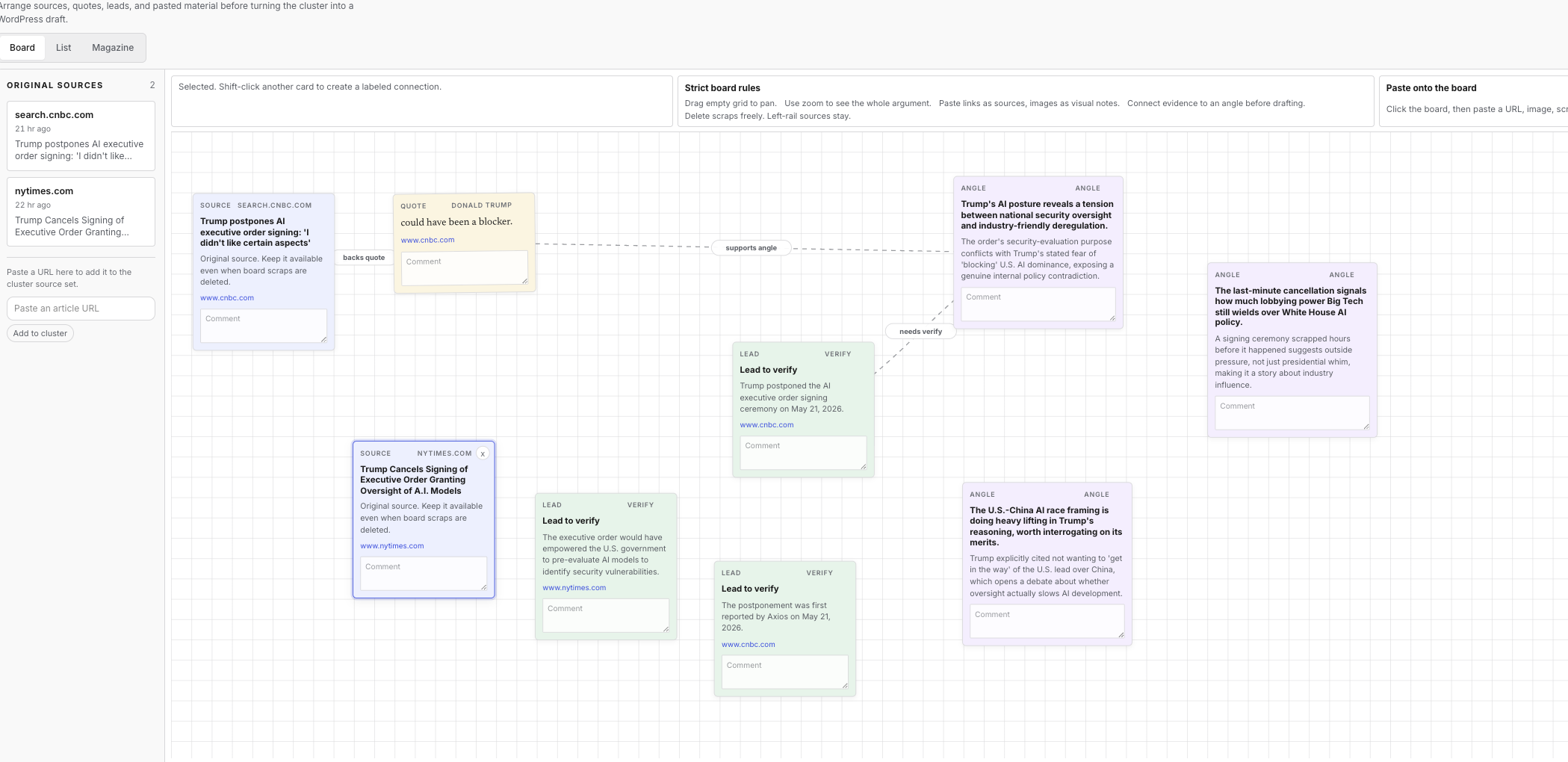
The last week brought the feature I’m proudest of: Research Mode.
The original loop — pick a cluster, hit “draft” — was skipping a step. The writer had to carry the story’s structure in their head and hope the model would reconstruct it. Research Mode replaces the linear notebook with a draggable board. Cards hold sources, quotes, leads, angles, and pasted material. Labeled connections between cards capture how the writer wants the piece to hang together. Board state persists per draft and feeds the draft-generation prompt as writer-arranged structure, not a flat note list.

The board makes the shaping step explicit. The prompt sees what the writer arranged. The same-day draft starts from a structure the writer chose.
That, plus autopublish workflows, admin controls, paid editor extensions, and plan-based invite links, got us to 223 commits in three weeks and a closed beta with real users publishing to real WordPress sites.
What I’d tell myself on day one
One sentence beats a roadmap. Write the mission in one sentence, put it at the top of your Agent.MD, and make everything — the AI, the team, the backlog — answer to it. The scope decisions that feel painful to make upfront are the ones that compound fastest once you make them.
Architecture bets are worth making early. The capability registry felt like premature abstraction. It wasn’t. Invest in the right contracts before the feature surface grows.
Desktop assumptions follow you to production. The performance work wasn’t refactoring — it was debt collection on a mental model that was never right for a multi-user web app. The question to ask every page is not “is this fast?” It’s “what does this page actually owe the user before first paint?”
AI is a senior engineer who never gets tired. You’re still the PM and the tech lead. The Agent.MD rule meant the AI couldn’t be faster than our discipline. That was the point.
Leave a Reply